












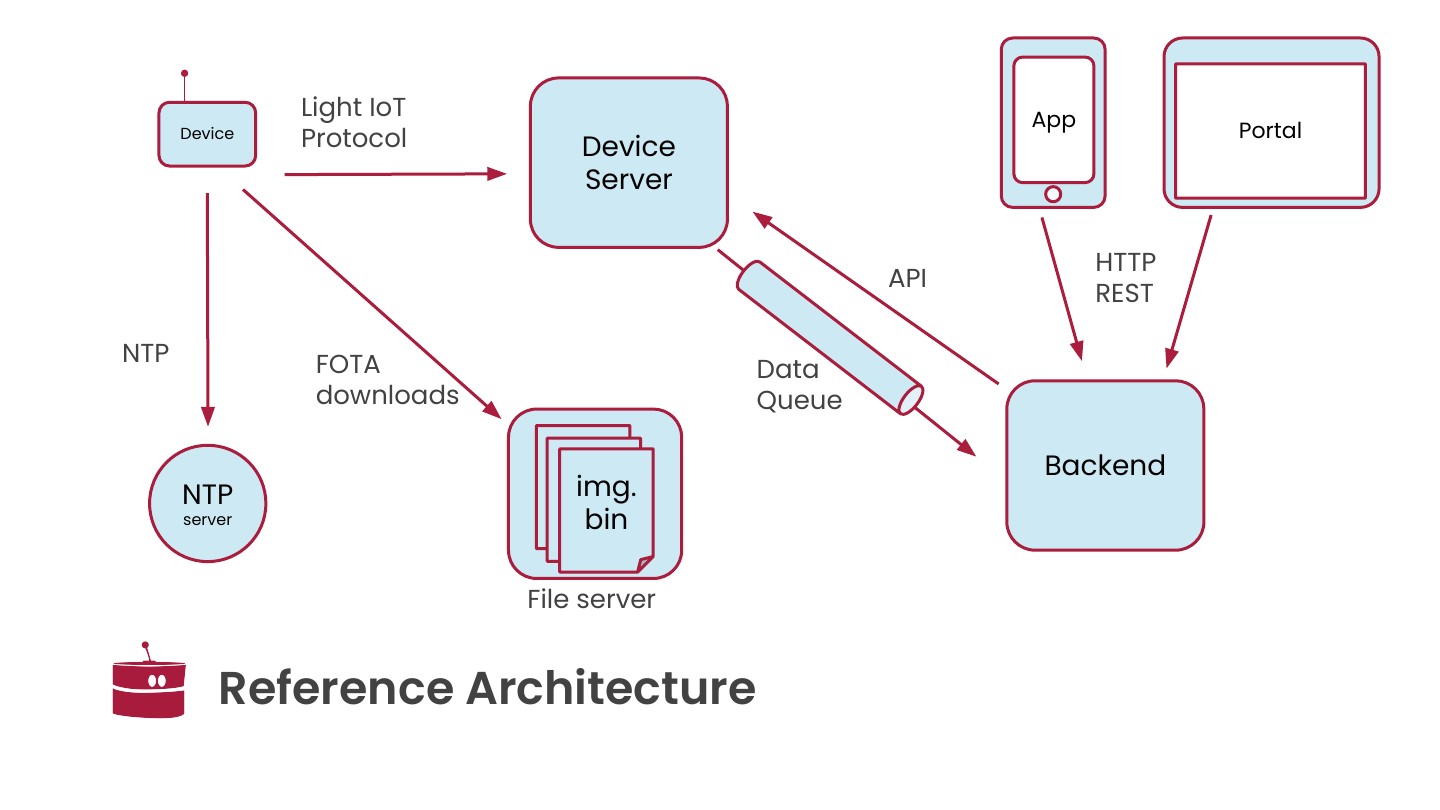





When you start a new IoT project, infrastructure is usually the last thing you want to spend time on.
What matters first is getting something valuable in front of customers and investors. A device that connects, sends data, maybe gets configured remotely, maybe even updates itself. Not a perfect architecture. Not something that scales to millions. Just something that works end-to-end.
So the default move is obvious: pick a managed platform, integrate the SDK, and move on.
You get dashboards, device registry, OTA, authentication, everything wired together. It saves weeks or months. You can focus on the product instead of building plumbing.
And to be clear: this is often the right decision.
The problem is not SaaS. The problem is that IoT decisions tend to stick.
Once devices are deployed, changing anything fundamental becomes difficult. Protocols, data models, and update mechanisms are not things you refactor easily. Devices are in the field, networks are unreliable, and customers already depend on the system.
What started as a shortcut becomes architecture.
So the real question is: how much control are you giving up early, and can you realistically take it back later?
This trade-off, convenience versus control, is at the core of most IoT systems.
The easy choice becomes structural
At the beginning, you need speed.
Managed platforms solve this very well. They remove friction and give you a working system on day one. Well, at least the good ones; some feel so hard to integrate that DIY can feel faster.
But they also make decisions for you:
- Your data goes through their pipeline.
- Your devices speak the protocols they support.
- Your behavior at the edge, including timing, retries, payload size, and failure modes, is often constrained by what the platform and its SDK allow.
At first, you do not care. Later, you do.
A typical example: everything works fine on Wi-Fi or LTE, then you move to NB-IoT or a weak coverage environment. Suddenly, every byte matters, every retry matters, and the “simple” SDK becomes a problem you cannot really fix.
Another one: you want to change how devices behave, but the data model or command model is baked into the platform. You can work around it, but you are no longer in control.
And then there is the roadmap. Features appear, disappear, pricing changes, limits show up, products are decommissioned, or companies are acquired.
None of this is dramatic on its own. But it accumulates.
The alternative is not “build everything yourself from scratch.” It is to build on components you control: open protocols, open-source stacks, and a device implementation you understand.
It is more work upfront. But it keeps your options open.
That is the core of the trade-off.
Protocol choice
Protocol selection is one of those structural decisions.
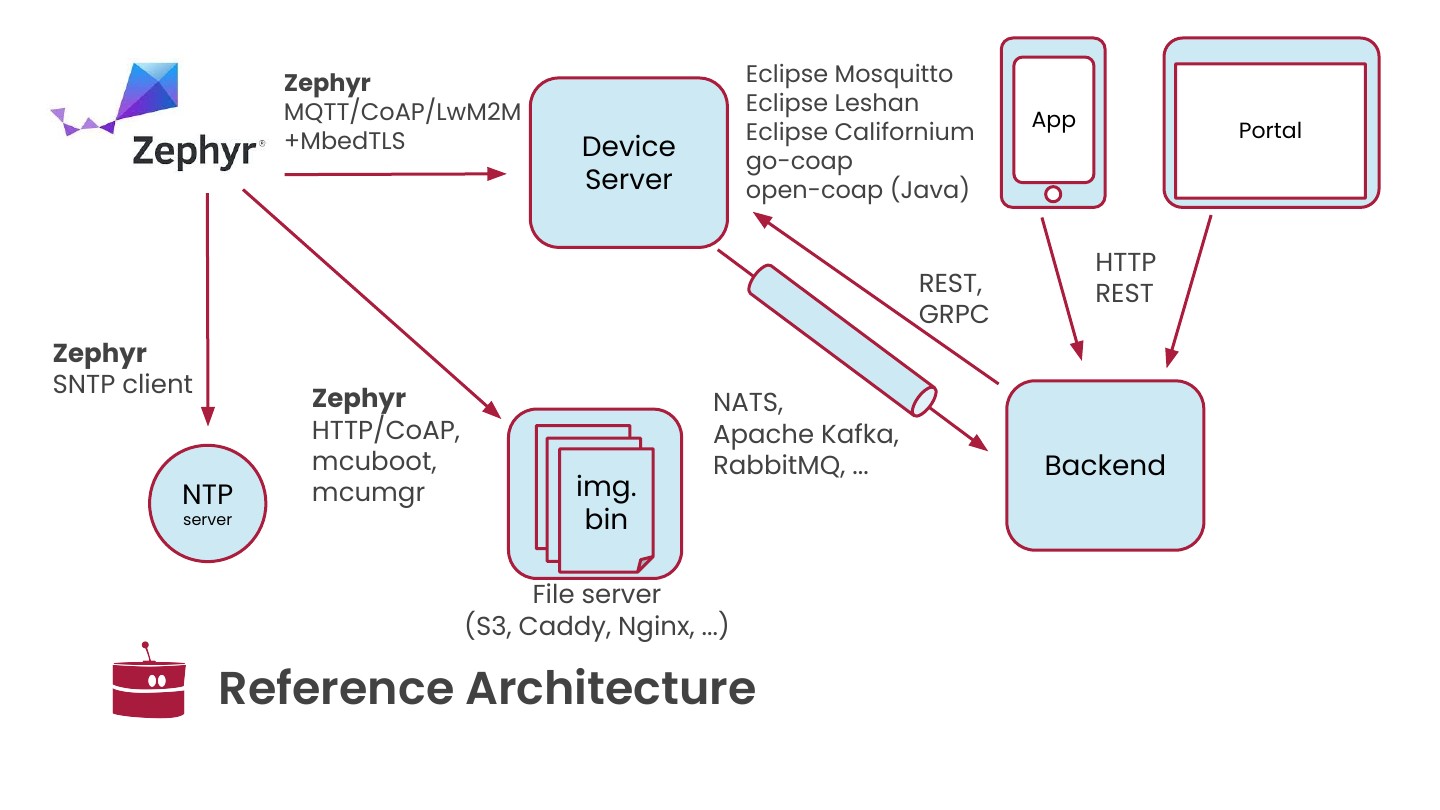
If TCP is cheap, such as Wi-Fi, Ethernet, or most LTE setups, MQTT is the obvious answer. It is simple, widely supported, and works well enough for most use cases.
But this only holds while TCP remains cheap.
As soon as you move to constrained environments, such as NB-IoT, Thread, poor radio conditions, or tight battery budgets, things change. Connections timeout. Latency increases. Retries become expensive. Power consumption increases.
This is where CoAP comes in: request/response, simple REST semantics over UDP, and control over retransmissions and timing. That control is not an obscure option for optimization. It is often the difference between a device that lasts months and one that drains its battery in weeks.
MQTT and CoAP are perfect if you control both ends: the device and the server. If not, then comes the interoperability question.
If you need to integrate with operators or existing ecosystems, Lightweight M2M becomes relevant. It adds a standardized object model and lifecycle management. It also adds complexity. It can feel heavy, but it opens the gate to low-power IP device interoperability.
And sometimes you do not even get to choose. With LoRaWAN or other non-IP networks, the transport is abstracted away, and your problem becomes payload encoding and efficiency.
The important point is simple: protocol choice defines your constraints. Power, latency, reliability, how much you can tune behavior at the edge, and how much your product integrates into an ecosystem are not things you want to “fix later.”
Device management is simpler than it looks
“Device management” sounds like a big topic. In practice, it boils down to a few patterns.
Devices send telemetry. That is your visibility: firmware version, sensor values, signal strength, errors. It is the cornerstone of monitoring.
The backend writes the configuration. That is how you change behavior without reflashing devices.
You trigger operations. Reboot, reset, start an update, maybe blink an LED so someone can identify the device in the field. These small features save a lot of support time.
And devices download files. Firmware is the obvious case, but also certificates, configuration bundles, or any asset you do not want to hardcode.
That is essentially it.
For simple devices, telemetry and configuration are often enough. Everything else comes later.
The challenge is not the number of features. It is making them reliable.
In practice, these patterns map quite naturally to the protocols you choose.
With MQTT, telemetry is typically published to device-specific topics, for example device/{unique ID}/data, while configuration and commands are received through subscribed topics such as device/{unique ID}/task. Using CBOR, you can define your own data model for telemetry. For tasks, a simple CBOR object can contain a unique ID and a description of the action to execute: read, write, FOTA, and so on. The device can then publish execution acknowledgements, including success or failure status, back to the telemetry topic.
With CoAP, the mapping is more explicit: telemetry can be modeled as resource updates, such as POST /data, and configuration as writable resources received from the server with POST or PUT. It looks closer to a REST API, which makes behavior easier to reason about, especially for web developers.
Firmware update: the test of ownership
If there is one place where ownership becomes real, it is firmware updates. This is where many systems fail.
A failed update can quickly escalate into a support issue, sometimes a logistical problem, sometimes a financial one. A 0.1% failure rate on a large fleet can be too much.
So you need something that can fail and retry safely.
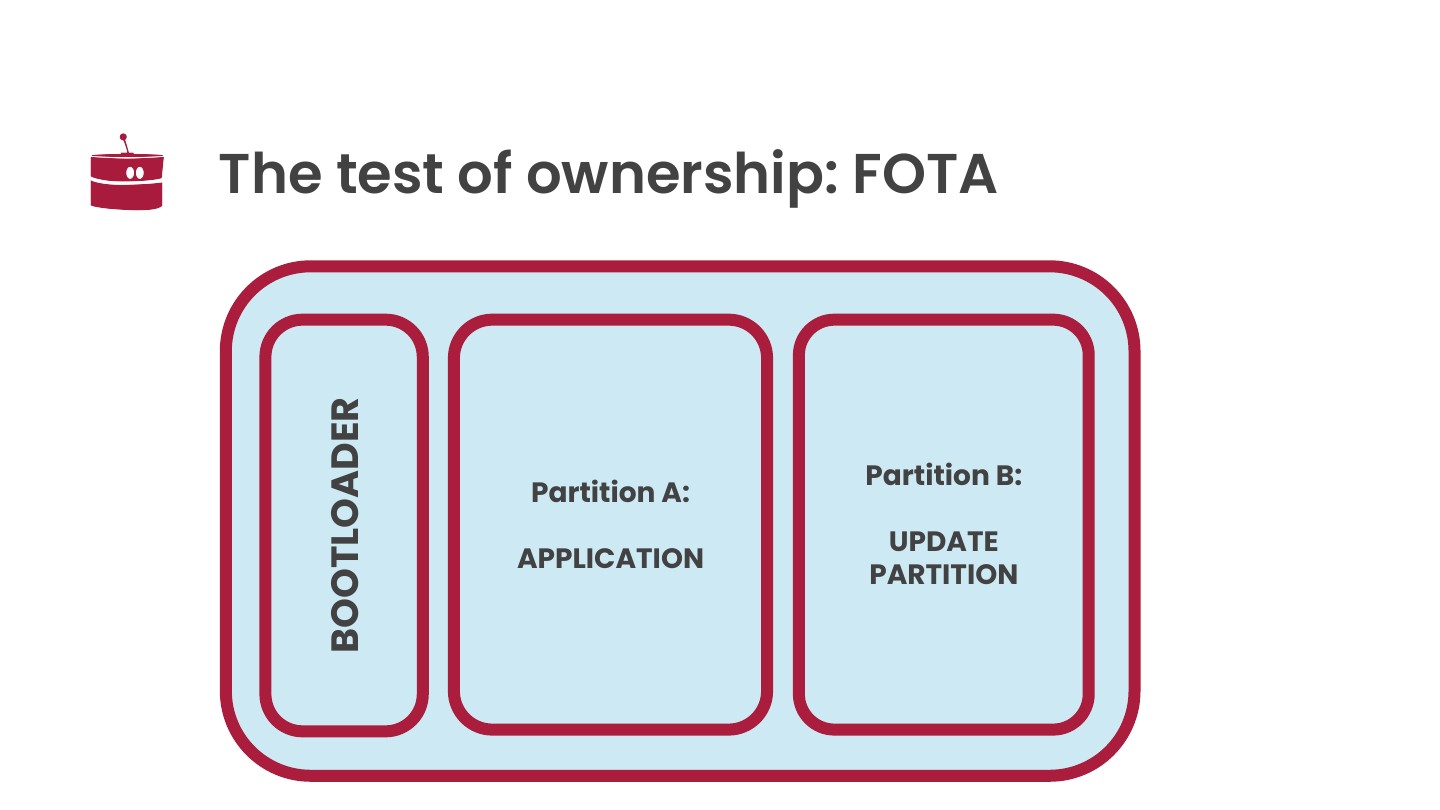
The standard approach is a bootloader with a dual-slot layout. One slot runs the current firmware, the other holds the update. You always keep a fallback.
With Zephyr, sysbuild makes this relatively straightforward. You build the bootloader and the application together, sign the images, and flash everything consistently.
MCUboot then verifies the signature before executing anything. That gives you a secure chain of execution.
But security is only part of the problem; what happens when the new firmware is broken?
MCUboot provides a simple and very effective model out of the box: test, confirm, revert.
A new firmware is downloaded to partition B. At reboot, MCUboot swaps the data in partition B to partition A. The device boots into the new code, but it is not yet confirmed. The application must explicitly confirm that it is working. If it crashes, reboots, or never confirms, the bootloader rolls back automatically on the next boot.
For many applications, you cannot test every real-world condition before deployment. Here, I am thinking about home automation or industrial devices that need to integrate with an ecosystem of other deployed devices on the same network. Timing changes, and things will fail in the field. Zephyr, sysbuild, and MCUboot provide this by default, with firmware signatures too.
Firmware delivery: let the device handle it
A common mistake is trying to let the server push firmware through control protocols. MQTT and CoAP are great for small messages. They are not designed for large binary transfers.
A more robust approach is to separate concerns.
Use your control channel to tell the device that an update is available. Provide a URL. Let the device download the firmware itself. This gives control to the device.
It can resume downloads after a disconnection. It can wait if the battery is low. It can choose the right moment based on its own state or local user agreement.
In unstable connectivity, this matters a lot. The backend might lose track of progress, but the device always knows where it is.
From first deployments to scale
With all these building blocks, it is actually not that hard to build a working system.
A device connects, sends telemetry, receives commands, downloads firmware, and updates itself. You have a backend, a few services, maybe a dashboard. That is for the first customers.
The difficulty starts when you scale.
At 50k+ devices, a single stateful server becomes multiple instances, and you need to introduce load balancing and shared session state.
Then you hit reconnection storms. A network outage happens, or you restart your backend, and thousands of devices reconnect at once. If you do not handle this properly, your system collapses under its own recovery.
Firmware updates will need some orchestration. You do not update everything at once. You roll out gradually, monitor failures, protect download capacity, and stop when something goes wrong.
Identity becomes a problem. How do you provision devices? Rotate keys? Handle factory processes? Reassign ownership? Wipe devices coming from RMA before reuse?
Telemetry becomes data engineering. You go from logs to pipelines, storage systems, and time series analytics.
At that point, the complexity is no longer in the device or the protocol. It is in operating the system.
Control has a cost
Building your own stack with open components is entirely doable today. The tools are there. The patterns are now well known. With a packaged OS like Zephyr, adding FOTA and secure connectivity to a modern microcontroller is a matter of days, with the benefit of customizing the solution to your exact needs.
You decide where your system runs: cloud, on-prem, or sovereign environments. You decide how data is stored and how long it lives. You decide how devices behave, how many retries, reconnections, and so on.
This matters in regulated environments and long-lived products, but even more for products with tight power budgets. Running on a non-rechargeable battery forces you to control every bit and behavior of the system.
But control is not free.
If you own the system, you own the problems: security, operations, compliance. There is no platform to absorb them for you.
That said, even with SaaS, you are still responsible for what you ship. You just have less control over how it behaves. So this is not only a technical choice. It is a strategic one.
If you optimize for speed and short-term delivery, managed platforms are often the right answer.
If you expect your system to live for 10-20 years, operate in constrained environments, or face regulatory requirements, giving up control early can become expensive later.
The important point is this:
If you are dealing with these trade-offs, choosing protocols, designing your OTA pipeline, or deciding how much to rely on a platform, this is the kind of work I do at ClunkyMachines.
Architecture, device-side implementation, or end-to-end system design.
Feel free to reach out if you want a second opinion before things get hard to change.